在第5章,我們討論了比特幣挖礦的能量消耗(有些人會說是浪費)是個潛在問題,經濟學家稱之為負外部性。我們估計比特幣挖礦要消耗幾十萬千瓦的電能。所以一個明顯的問題是,這些用來解謎運算的工作量是否對社會有所貢獻?這其實是一個資源再生循環的問題,也會增加社會對加密數字貨幣的政策支持。當然,這個解謎算法也必須滿足幾個基本的要求,才能夠在一個共識協議裡被使用。
以前的分佈式計算項目
在比特幣誕生好多年之前,就有利用空閒的電腦〔或者叫「空閒週期」(spare cycle)〕來做一些其他工作的想法。表8.1列出了最受歡迎的幾個志願者運算項目。所有這些項目都有一個特性,使得它們適合成為解謎算法的運算。具體來說,它們需要解決的都是一種「大海撈針」型的問題,可能的答案存在於一個非常大的空間(或者說範圍),搜索空間的每一小部分都可以進行並行的快速驗證。最有名的例子是在SETI@home網站上,志願者們被分配一小段無線電信號,用閒置的個人電腦來分析這段信號可能存在的模式以尋找外星文明,同時分佈式計算網站(distributed.net)的志願者被分配一小段可能的私鑰來進行驗證。[1]
志願者運算項目,成功地把一個很大的計算任務拆分成小份的任務,然後分配給每一個志願者進行運算檢查。事實上,這種模式在一個特別的叫作伯克利開放式網絡計算平台(Berkeley Open Infrastructure for Network Computing,簡稱BOINC)上是很普遍的,這個平台被開發出來就是用來給不同的個體分發小份額計算工作的。
在這些應用裡,志願者們主要都是被解決某個問題的興趣所吸引,即使這些項目通常也會設立一個排行榜來讓人們炫耀他們所貢獻的算力。排行榜也導致一些人在自己的工作量上作弊,有一些被報告的工作量其實並沒有實際完成,這也使得有些項目再分配一些額外的工作去檢查網絡上的這種作弊行為。金錢,是加密數字貨幣分佈式計算應用的動力,只要技術上是可能的,一定會有參與者嘗試去作弊。
表8.1 熱門的志願者運算項目
有效工作量證明的挑戰
有了這些成功的項目,我們可以嘗試簡單直接地利用這些解決問題的成功方法。例如,在SETI@home的項目中,志願者們被分配一小段無線電信號監聽去尋找外星人,我們可以判斷,外星人存在的概率,要比解謎算法找到「獲勝」答案並且允許找到答案的礦工去創建一個區塊的概率小很多。
但這個想法有幾個問題。首先,並不是所找到的答案都有同樣的概率成為「獲勝」的答案。參與者可能會意識到有特定區域會有更高概率找到異類,那麼參與者就會有傾向性,只針對一些能產生不同尋常結果的區域進行分析。對於一個中心化的項目來說,參與者被分配工作,所以所有的區域最終都會被分析(當然對最有希望的區域會予以優先考量)。對於挖礦來說,任何礦工可以隨意嘗試任何區塊,所以礦工會先湧向最有希望的區塊。如果更快的礦工知道他們可以先嘗試最有希望的區塊,這就意味著解謎算法可能不是一個過程無關的算法。比特幣的解謎算法與之相比就有不同,比特幣的解謎算法中用來產生一個有效區塊的臨時隨機數都是完全平等的,所以所有礦工都會隨意選擇一個臨時隨機數去嘗試。這個問題展示了我們之前都已經習以為常的比特幣解謎算法的一個主要特徵:一個機會均等的解謎區域。加 入 會 員 微 信
其次,考慮到SETI@home項目中存在著固定的數據量需要被分析的問題,這些數據基於射電望遠鏡(radio telescope)的觀察。隨著挖礦算力的不斷增長,有可能某一天就沒有需要加工的數據了。比特幣在這方面也有不同,比特幣算法有無限的SHA-256解謎可以被創造出來,這就說明了另一個重要的特徵需求:永不枯涸的解謎庫。
最後,考慮到SETI@home的項目中,有一個受信任的中心化的管理員機構,負責發現新的無線電信號並判斷志願者們應該研究的內容。同樣,由於我們使用解謎算法來構建一個共識機制算法,不可能假設一個中心化的機構來管理所有的解謎,這樣我們就需要所有解謎的最後一個特徵:通過算法自動生成。
哪種志願者運算項目可能適合解謎算法
回到表8.1,我們可以清楚地看到,像SETI@home和Folding@home這樣的項目不太適合去中心化的共識機制協議,兩者都被證明了缺乏我們所列出的上述三個特性。distributed.net上的暴力破解密碼學項目可能適用,雖然它們通常被某些公司用來做某種加密算法的安全評估,但是不能通過算法自動生成。我們可以通過算法自動生成被暴力破解的加密方法,但是某種程度上這就是SHA-256不完全原像(partial preimage)算法已經做過的事,並且它沒有任何有益的功能。
那就只剩下互聯網梅森質數大搜索(Great Internet Mersenne Prime Search,簡稱GIMPS)項目了,這個最具備可用性。這個辦法的挑戰是通過算法自動生成(找到下一個比當前最大質數更大的質數),以及謎底空間是不可窮盡的。事實上,質數的尋找確實是無窮的,因為質數的個數已經被證明是無限個的(特別是梅森質數是無限量的)。
梅森質數方法的唯一缺點,是需要花費很長的時間來尋找梅森質數,並且梅森質數非常罕見,事實上在過去18年裡,梅森質數大搜索項目一共才發現了14個梅森質數,顯然在區塊鏈上每年才增加不足一個區塊是不可行的。這個問題看起來是缺乏可調節的難度特性,我們在8.1節討論過這個特性是非常關鍵的。無論如何,類似於尋找質數這樣的解謎算法,看起來是可行的。
質數幣
到2015年為止,唯一在實際中被應用的被證明具有有效工作的系統是質數幣(Primecoin)。質數幣的主要挑戰是為質數找到一個「坎寧安鏈」(Cunningham chain)。坎寧安鏈是指k個質數的序列P1,P2,…,Pk,以使得Pk=2Pi-1+1。也就是說,你選一個質數,然後把這個質數乘以2再加1以得到下一個質數,直到你得到一個和數(非質數)。含有2,,5,11,23,47就是一個長度為5的坎寧安鏈,按照這個規則所獲得的第六個數字95並不是質數(95=5×19)。最長的已知的坎寧安鏈的長度是19(從79,910,197,721,667,870,187,016,101開始),有一個被推測以及被廣泛認可但沒有被證明過的理論認為,存在一條任意的長度為k的坎寧安鏈。
現在,要把這個理論變成一個可計算的解謎算法,我們需要三個關鍵的參數m、n和k,稍後我們會具體解釋。對於給定的一個解謎挑戰x(上一個區塊的哈希函數值),我們選擇x上的前m位數。我們可以認為任何長度為k的鏈或者大於k的答案是正確的,這條鏈上的第一個質數是一個n位質數並且和x一樣有m位的首段數據(n≥m)。值得注意的是,我們可以調整n和k的值,來讓這個解謎變得更加困難。增加k的值(需要的鏈的長度)使得問題難度指數型增長,而增加n的值(鏈上的第一個質數的長度)使得問題難度線性增長,這就可以讓我們對問題難度進行微調。其中,m的值只需要足夠大,使得在知道前一個區塊的值之前的預先計算方法變得沒有意義。
其他我們所討論的屬性看起來已經都有了:結果可以很快被校驗,問題本身是無關過程的,題庫可以無限大(假設對質數分佈的知名數學推導是正確的),然後解謎可以通過算法做到自動生成。實際上,這個解謎算法已經被質數幣用了兩年,並且對許多給定的k值產生了坎寧安鏈裡最大的質數。質數幣還做了進一步的擴展,在其工作量證明中涵蓋了其他類似的質數鏈,包括「第二」坎寧安鏈,其中Pi=2Pi-1。
這驗證了在某些限定的情況下,有效工作量證明是具有實際運用的。當然,尋找大的坎寧安鏈有用與否,是有爭議的。坎寧安鏈當然也代表了我們已知數學知識寶庫的一小部分,其在未來可能會有一些應用場景,但在目前還沒有實際的應用出現。
永久幣和存儲量證明
另外一種有效工作量證明叫存儲量證明(proof of storage),也被稱為可恢復性證明(proof of retrievabitlity)。不同於需要一個單獨計算的解謎算法,我們可以設計一個需要存儲大量數據被運算的解謎算法,如果這個數據是有用的,那麼礦工在挖礦硬件設備上的投資就可以被用於大範圍分佈式存儲和歸檔系統。
讓我們看一下永久幣(Permacoin),這是第一個用於共識機制的存儲量證明方案。首先我們討論一個大文件F,我們假設所有人都認可F的價值並且這個文件不會被改變。例如,當一個加密數字貨幣上線時,由一個可信任的分發者選擇F,這有點類似於任何一個加密數字貨幣啟動時都需要一個創世區塊,理想狀況下這個文件會具備公共價值。例如,大型強子碰撞(Large Hadron Collider,簡稱LHC)的實驗數據,這個數據已經達到了幾百拍字節(petabytes,用PB表示)的大小,對這些數據的備份是很有價值的。
當然,因為F存儲量非常巨大,大多數參與者都無法對整個文件進行存儲,但我們已經知道,在不需要瞭解整個文件的情況下,如何使用密碼學裡的哈希函數來確保每個人都對F認可。最簡單的方法是,每個人都認可H(F), 但更好的方法是用一個大型梅克爾樹來代表F,所有的參與者都認可梅克爾樹的根值。現在,每個人都認可F的價值,證明F的任意一部分是正確的就變得很有效率。
在永久幣系統中,每一個礦工M存儲著任意F文件的子集FM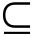 F。為了實現這一點,當礦工產生一個公鑰KM來接受資金時候,他們就對該公鑰進行哈希運算以生成一個區塊FM的虛擬隨機數集,他們必須存儲這個數集以實現挖礦的目的。這個子集就會變成某個固定數量的區塊k1的一部分,我們必須在這裡做一個假設,當礦工開始挖礦的時候,他們有辦法獲得這些區塊——可能是從一個標準文件源地址下載下來(見圖8.2)。
F。為了實現這一點,當礦工產生一個公鑰KM來接受資金時候,他們就對該公鑰進行哈希運算以生成一個區塊FM的虛擬隨機數集,他們必須存儲這個數集以實現挖礦的目的。這個子集就會變成某個固定數量的區塊k1的一部分,我們必須在這裡做一個假設,當礦工開始挖礦的時候,他們有辦法獲得這些區塊——可能是從一個標準文件源地址下載下來(見圖8.2)。
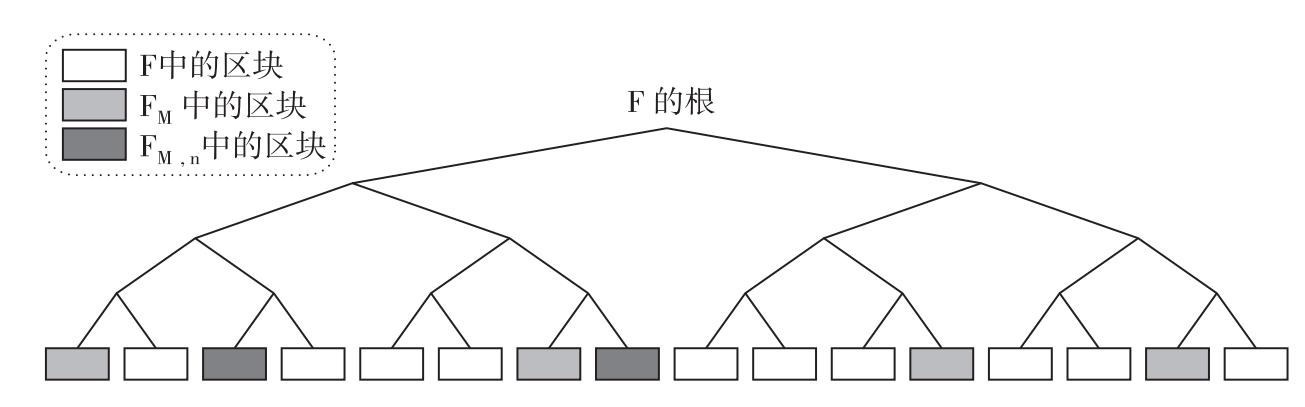
圖8.2 在永久幣系統中選擇一個文件的隨機區塊
註:在這個案例中,k1=6,k2=2。在實際應用中,這些參數會大很多。
一旦礦工在本地存儲了FM,這個解謎算法就非常類似於傳統的SHA-256挖礦了。給定前一個區塊的哈希值x時,曠工選擇一個臨時隨機數n,將其進行哈希運算並產生一個虛擬隨機數子集FM,nFM,這個子集包含了k2<k1個區塊。值得注意的是,這個子集是由所選的臨時隨機數和礦工的公鑰共同產生的。最後,礦工對n以及Fk中的區塊,進行SHA-256的哈希函數運算,如果計算的結果是低於目標難度的,那麼也就意味著他們找到了一個有效的方案。
校驗一個解謎算法的結果需要以下幾個步驟:
● 校驗FM,n是由礦工的公鑰KM和臨時隨機數n共同產生的。
● 通過檢驗其在梅克爾樹節點到全局統一的樹根路徑,來檢驗FM,n中的每一個區塊是正確的。
● 校驗H(FM,n∥n)的值比目標難度要小。
我們很容易看出,為什麼解謎過程需要礦工在本地存儲所有的FM,n。對於每一個臨時隨機數,礦工都需要計算FM,n中隨機子集的哈希值,如果通過遠程訪問一個存儲空間來獲取文件,就會非常慢,幾乎不可能實行。
不同於Scrypt算法的案例,如果k2足夠大,並沒有一種可行的類似於時間內存的權衡方案。如果礦工僅僅在本地存儲了一半的FM,並且k2=20,那麼在他們找到一個不需要從網絡中取回任何文件區塊的臨時隨機數之前,他們必須要嘗試100萬次,降低一定量的存儲負擔會以計算量指數型增長為代價。當然,由於k2梅克爾樹路徑要在所有的路徑中被傳輸和校驗,如果k2設得太大,也會使運算變得非常低效。
k1的設定也可以有所權衡。更小的k1意味著礦工需要更少的本地存儲空間,因此這種挖礦就更加民主化(更多的人可以參與)。然而,這也意味著,大量的礦工即使有能力提供更大的存儲空間,他們也沒有動力去存儲多於k1個F區塊。
同樣,這是一個對完整的永久幣做了細微簡化的方案,但是對我們理解整個設計的關鍵部分來說是足夠的了。最大的應用挑戰,當然是找到一個合適的大文件,這個文件要有一定的重要意義,同時也是公共的,需要保存多個備份。如果F文件本身隨著時間的推移會發生變化,或者隨著時間的變化而調整難度,這樣會使方案變得更加複雜。
長期的挑戰和經濟意義
總結一下本節內容,有效工作量證明是一個非常自然的目標。考慮到一個好的共識機制所需要的其他解謎算法,實行起來也有相當大的挑戰。即使如此,至少本文所舉的兩個案例——質數幣和永久幣——在技術上是可行的,雖然它們也都有一些技術方面的缺陷(主要都是需要更長的時間去驗證解謎結果)。此外,對比在比特幣挖礦中動輒數百萬美元的投入以及大量電力的消耗,這兩種加密數字貨幣的應用都對社會公益有一些貢獻。
有效工作量證明是否應該是純公益的,有一個有趣的經濟學方面的爭議。在經濟學中,公益的意思是非排他性的,也就是說所有人都可以參與使用,並且是非競爭性的,對公益的其他用途不應該影響其本身的價值。一個經典的例子就是燈塔。
我們這裡所討論的案例,比如蛋白質折疊(protein folding)[2],就不是一個純公益的項目,因為有一些公司(比如大的製藥公司)可以從中獲利。實質上,這些機構挖礦的成本會相對變低,因為它們可以獲取其他人無法獲得的額外利益。
[1] 大約有500萬人參加這個計劃,包括譯者本人。——譯者注
[2] 蛋白質折疊問題被列為「21世紀的生物物理學」的重要課題,它是分子生物學中心法則尚未解決的一個重大生物學問題。——譯者注