另一種常見的評論是大腦的生物設計細節實在是太複雜了,使用非生物技術模擬難以建模和仿真。例如,托馬斯·雷寫道:
大腦的結構和功能或其組成部分不能分割。循環系統為大腦提供基本生活支持,但它也提供了荷爾蒙,這是大腦化學信息處理必不可少的元素。神經元的膜是一個結構性特點,它確定了神經元的範圍和完整性,同時也是沿著這層膜的表面向兩極傳播信號。這個功能是結構性的,也是生命之本,不能和信息處理分開。17
雷接著描述了幾個大腦的「化學交流機制的廣闊頻譜」。
事實上,所有這些特點可以很容易地進行建模,並且在這方面已經取得很大進展。數學是中間語言。將數學模型轉化為等價的非生物機制(比如計算機模擬和使用晶體管的電路),這是一個相對簡單的過程。比如說,循環系統釋放激素,這是一個帶寬非常低的現象,它的建模和複製都不難。某些激素的血液水平以及其他化學影響參數水平可以同時影響許多突觸。
托馬斯·雷得到一個結論,「一個金屬計算系統工作在完全不同的動態屬性上,而且永遠無法精準地複製大腦功能」。隨著神經生物學、腦掃瞄、神經元相關領域,神經區域建模,神經元電子通信,神經植入物及相關事業的發展,我們發現,我們有能力在任何想要的精確度上複製生物信息處理的突出功能。換言之,複製功能可以「滿足」任何想得到的目的或目標,包括圖靈測試。另外,有效實現數學模型所需的計算能力遠遠低於對生物神經元簇建模的理論值。在第4章中,我回顧的一些大腦區域模型(瓦特的聽覺區域、小腦等)並證明了這一點。
大腦複雜度。托馬斯·雷指出,我們可能很難建立一個相當於「數十億行代碼」的系統,他認為人類大腦大概就在這個複雜度。然而,這個數字是被誇大了的,我們已經知道,創造大腦的基因組僅僅包含大約3千萬~1億字節的獨特信息(8億沒有經過壓縮的字節,這顯然存在大量的冗余),其中大概2/3的內容用於描述大腦的運作。正是因為包含大量隨機因素的自組織過程(就像現實世界表現的那樣),使得相對少的設計信息擴大到數千萬億字節信息,就像一個成熟的人腦所表現的那樣。類似的,在一個非生物實體中創造人類級別智能的任務,不僅是創建一個由無數規則和代碼組成的龐大的專家系統,而是一個能學習的、無序的、自組織的系統,一個有生物創造力的系統。
雷繼續寫道:「有些工程師可能會提出帶有球殼狀碳分子開關的納米分子器件,甚至是類DNA的計算機。但我相信他們絕不會想到神經元。與我們開始說的分子相比,神經元的結構大得多得多。」
這僅僅是我自己的觀點:人類大腦逆向工程的目的不是要複製消化或其他笨拙的生物神經元過程,而是要瞭解它們處理信息的關鍵方式。現在有許多項目都證明了這個觀點的可行性。隨著其他技術能力的提高,模擬的神經簇的複雜度增加了好幾個數量級。
計算機固有的二元論。紅木神經科學研究所的神經專家安東尼·貝爾闡明了在我們用計算來建模和模擬大腦上有兩個挑戰。第一個是:
計算機本身就是一種二元實體,它的物理結構被設計成不會影響到用來執行計算的邏輯結構。根據以往的調查,我們發現,大腦並不是一個二元實體。計算機和程序能分開,但思維和大腦是一個整體。因此大腦不是一個機器,這意味著它不是一個實體化的確定模型(或計算機),因為在模型中,物理實例不影響該模型(或程序)的執行。18
很容易看出這個論點的破綻。計算機能將程序和執行計算的物理實體分離的能力是一種優勢,而不是一種限制。首先,我們有專用電路的電子設備,其中「計算機和程序」不再是兩個東西,而是一個整體。這種設備不是用編程驅動,而是為特定算法設計的硬件。請注意我不僅僅指在計算機只讀存儲器中的軟件(稱為「固件」),這種設備在手機或袖珍型計算機中也能找到。在這樣的一個系統中,電子器件和軟件仍可被視為二元,即使程序不能輕易地進行修改。
我提到用根本不能進行編程的專有邏輯代替系統,例如用於某些應用程序的特定的集成電路(例如用於圖像和信號處理的)。用這種方法執行算法能節約成本,而且許多電子消費產品使用這樣的電路。不過雖然可編程計算機需要的成本更高,但是提供了靈活的軟件改變和升級。可編程計算機可以模仿任何專用系統的功能,包括我們發現的關於神經元件、神經元、大腦區域的算法(通過大腦逆向工程的努力而實現)。
有人認為邏輯算法和物理設計存在固有聯繫的系統「不是機器」,這種看法是不對的。如果人們可以理解該系統的工作原理,用數學術語對其建模,然後在另一個系統中創建實例(無論其他系統是不可改變的專用邏輯機器還是可編程計算機軟件),那麼我們可以認為這是一台機器,當然也是一個實體,其功能可以在機器中重新創建。正如在第4章廣泛討論的,我們完全能從分子間的相互作用開始來發現大腦的運作原理,並對其成功地建模和模擬。
貝爾指出計算機的「物理結構被設計成不干擾它的邏輯結構」,這暗示了大腦並沒有這種「限制」。他是正確的,我們的思想確實協助建立大腦,正如我剛才所說,我們可以在大腦動態掃瞄中觀察到這一現象。但我們可以用軟件輕易建模和模擬大腦的可塑性,無論是物理方面還是邏輯方面。事實上,電腦軟件能和物理實體分開,這是一個架構優勢,因為這允許相同的軟件應用於不斷改善的硬件上。計算機軟件就像大腦中的改變電路,也能自我修改,還能升級。
同樣的,在軟件沒有變化時,計算機硬件也可以升級。大腦相對固定的架構才是嚴重的限制。雖然大腦能夠創建新的連接以及神經遞質模式,但是其化學信號低於電子100多萬倍,適應我們頭骨的神經元間連接的數量也有限,也不能升級,除非通過我前面提到的和非生物智能的合併。
層次和循環。貝爾還評論了大腦的複雜性:
分子和生物物理過程控制神經元對傳入尖峰的敏感性(包括突觸的效率和後突觸響應)、神經元產生尖峰的興奮性、產生的尖峰模式以及新的突觸形成的可能(動態布線),這裡僅僅列舉了4個子神經元層最明顯的參考值。除此之外,我們看到,一些跨神經元的作用,比如局部電場、氧化氮的跨膜擴散,分別影響著連貫的神經激勵(coherent neural firing)和傳遞給細胞的能源(血流量),後者直接影響著神經元活動。
還可以繼續列舉很多例子。我相信,任何人只要認真研究神經調節、離子通道或突觸機制,肯定就不會認為神經元層面是一個單獨的計算層面,甚至會發現它是一個有用的描述層面。19
雖然貝爾在這裡指出,神經元並不是模擬大腦的適當層次,但是他主要想說的和托馬斯·雷的論點很相似:大腦比簡單的邏輯門複雜。
對此,他作了詳細闡述:
有人認為為了描述大腦的功能,一個結構性的水或一個量子一致性是必需的細節,這種觀點顯然很荒謬。但是,如果在每一個細胞中,分子來源於子分子過程的系統功能,如果一直使用這些過程來遍歷大腦,來反映、記錄和傳播的時空相關性分子的波動,來增強或減弱反應的可能性和特異性,那麼這種情況就與邏輯門有著質的不同。
他在某個層面反駁了神經元和神經元間連接的簡單模型,這些模型應用於許多神經元項目。大腦區域模擬沒有使用這些簡單模型,而是使用基於逆向工程結果的逼真數學模型。
貝爾真正的觀點是:大腦是非常複雜的,還有很多後繼反應,因此大腦是難以理解的,也很難對其建模和模擬其功能。在貝爾看來,主要問題是,他不能解釋大腦設計的自組織、無秩序、不規則特性。可以肯定的是,大腦非常複雜,但是很多情況下只是看起來複雜而已。換言之,對大腦的設計原則比表面看起來的要簡單些。
為了理解這一點,我們首先考慮大腦組織的不規則性質,這在第2章討論過。在創建一個模式或設計時,分形是一個迭代使用的規則。該規則通常很簡單,但由於迭代使得設計顯得很複雜。一個著名的例子是由數學家伯諾伊特·曼德爾布羅設計的Mandelbrot set。20 Mandelbrot set的可視化圖片非常複雜,在複雜的設計中嵌套複雜的設計。當我們看Mandelbrot set的一個圖像時,隨著看的細節越來越細,但複雜度卻永遠不會消失,我們可以看到一個同樣的複雜度。然而關於所有複雜度的公式卻是驚人的簡單:Mandelbrot set用一個簡單的公式來描述,這個公式是Z=Z2+C,Z是複數,C是常量。公式是迭代使用的,圖9-1所示的曲線圖描述了結果的二維點。
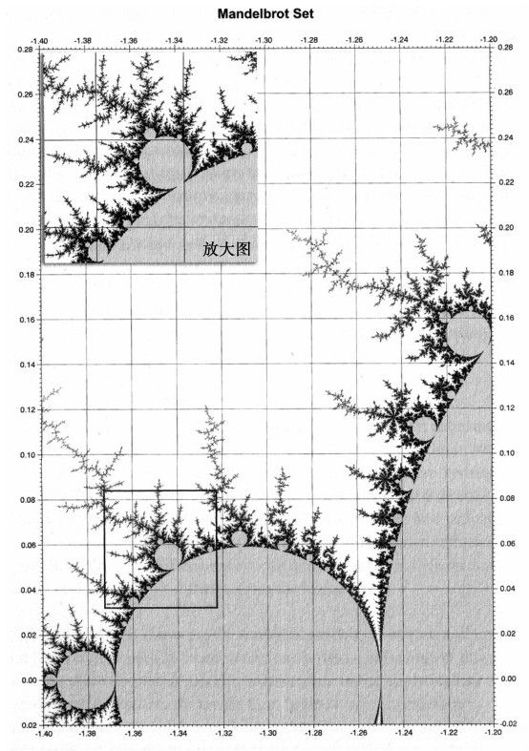
圖 9-1
關鍵點在於,一個簡單的設計規則就可以創建巨大的複雜度。史蒂芬·沃爾夫勒姆表達了相似的觀點(見第2章),他在細胞機器人上使用的規則也很簡單。這種見解抓住了大腦設計的真諦。我曾經說過,經過壓縮的基因組只是一種相對緊湊的設計,甚至比當代的一些軟件程序還小。但是正如貝爾所指出的,大腦的實際實現卻要複雜得多。就像Mandelbrot set一樣,當越來越精細地觀察大腦的特徵時,我們仍然能夠很清晰地看到每個層次的複雜度。從宏觀的層面來看,連接的模式看起來很複雜;從微觀的層面看,一個神經元單個部分的設計(比如樹狀突)也同樣複雜。我提到過,如果想描述一個人大腦的狀態,我們至少需要萬億字節的信息;但是如果只是設計大腦,那麼只需要千萬字節的信息。因此,大腦所表現出來的複雜度與設計它所需的信息的比率至少是10 8:1。雖然大腦信息的開始階段充滿大量的隨機信息,但隨著大腦與環境發生複雜的相互作用(人的學習和成熟),這些信息才變得有意義。
實際設計中的複雜度是由設計階段的壓縮信息(基因組和支持分子)所決定的,而不是由迭代使用設計規則所創建的模式來決定的。我認為,雖然基因組中約有3千萬~1億字節(當然比Mandelbrot set中定義的6個字符複雜得多),但這並不代表它是一個簡單的設計。不過這個複雜度我們能夠通過技術來管理。很多觀察家被大腦物理實體表現出來的複雜度所迷惑,他們沒有認識到,設計的不規則特性意味著實際的設計信息遠比我們從大腦中看到的信息簡單。
我在第2章中也提到,基因組的設計信息有一種隨機的不規則性,這意味著當每一次迭代規則時,都存在著一定的隨機性。也就是說,例如,只有很少的基因組信息用於描述小腦(cerebellum)的布線圖,而小腦包含了大腦中半數以上的神經元。很小一部分基因用於描述小腦中4核細胞的基本模式,而且從本質上說,「重複這種模式幾十億次,在每個重複過程中都存在一些隨機的變化」。結果看起來非常複雜,但所需的設計信息其實相對較少。
試圖將大腦設計與傳統的計算機相比較將是一個令人沮喪的行為,在這點上,貝爾的判斷是正確的。大腦並不是那種典型的自上而下(模塊)的設計模式。它利用隨機的不規則的組織結構創建一個無序的進程,這是一個沒有可預見性的進程。若一個成功的數學模型用於模擬與仿真無序系統,用於瞭解諸如天氣和金融市場等現象,這個模型同樣也適用於大腦。
貝爾沒有提到這種方法。他認為,大腦與傳統的邏輯門和傳統的軟件設計相比有著巨大的差異,因此他得到了一個沒有經過充分論證的結論,即大腦不是機器,也就不能用機器去模擬它。儘管他說得很對,標準邏輯門和傳統模塊化軟件的組織並不是分析大腦的恰當方法,但這並不意味著我們無法在計算機上模擬大腦。因為我們可以用數學術語來描述大腦的運行原則,而我們又可以在計算機上對任何一個數學過程建模(包括無序過程),所以我們能夠實現這種模擬。而且事實上,這些工作一直在做,並且一直在進步中。
儘管貝爾持有懷疑態度,但是他對於我們將更好地理解我們的生理和大腦,並對它們加以改進的觀點,表達了一種謹慎的信心。他寫道:「會不會出現一個超人類的年齡?為了這個目標,要有一個強大的生物先例出現在生物進化主要的兩步中。第一,真核與原核細菌的共生;第二,在真核生物中出現多細胞生命形式……我相信,一些不可思議的事情(像超人類的壽命)也許會發生。」