曾經在收集數據的項目中,用過 mongodb 的數據存儲,但是當數據很大的時候,還是比較的吃力。很可能當時的應用水平不高,也可以是當時的服務器不是很強。 所以這次能力比以前高點了,然後服務器比以前也高端了很多,好勒 ~再測試下。
(更多的是單機測試,沒有用複製分片的測試 ~)!
相比較 MySQL,MongoDB 數據庫更適合那些讀作業較重的任務模型。MongoDB 能充分利用機器的內存資源。如果機器的內存資源豐富的話,MongoDB 的查詢效率會快很多。
這次測試的服務器是 dell 的 r510!
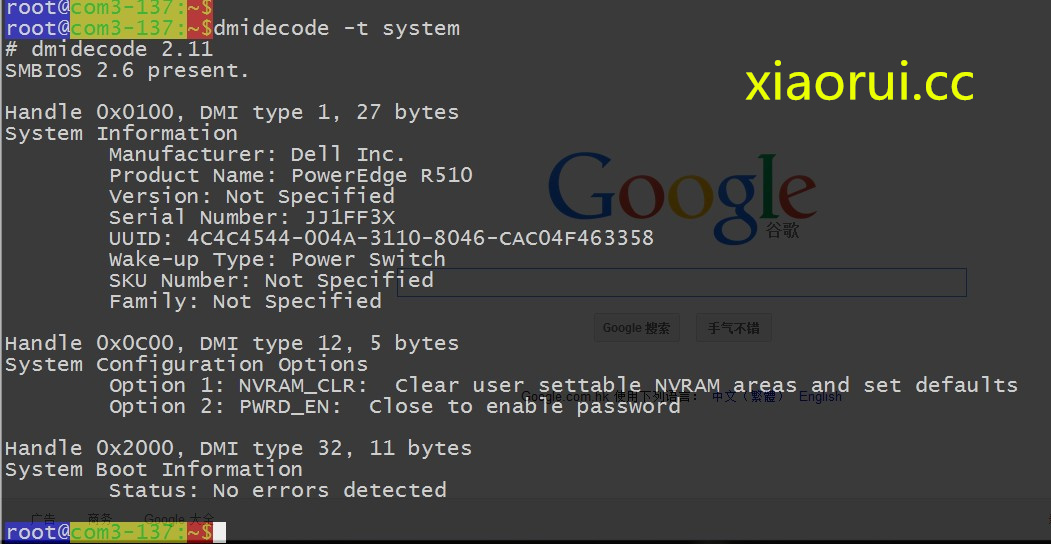
圖片 15.1 pic
內存還行,是 48 G 的,本來想讓同事給加滿,但是最終還是沒有說出口 ~
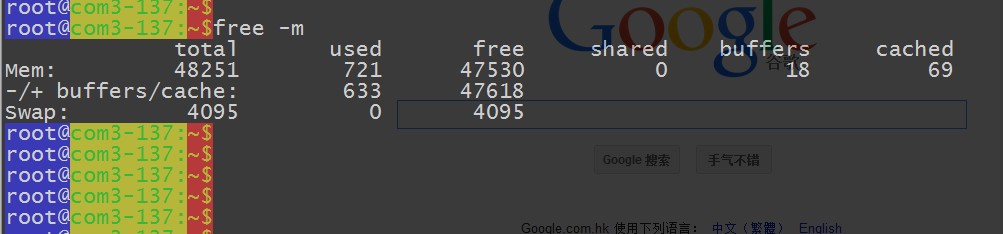
圖片 15.2 pic
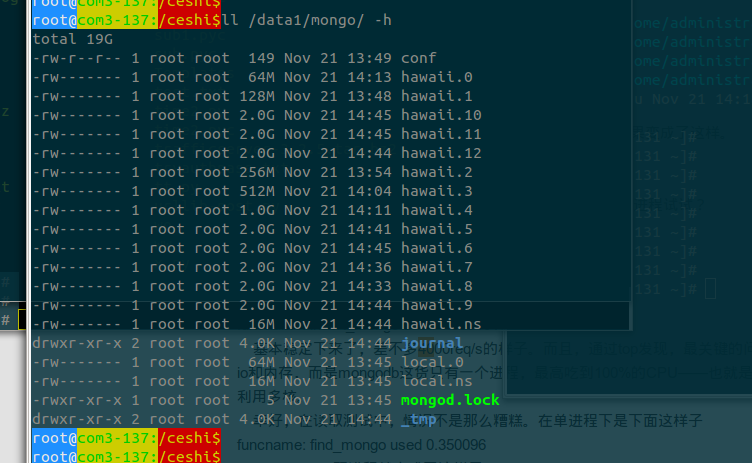
磁盤是 10 個 2T 的,但是因為格式化的時間太久了,哥們直接把其他的硬盤給拔出來了,就用了三個盤。。。data 目錄沒有做 raid,是為了讓他們體現更好的硬盤速度。
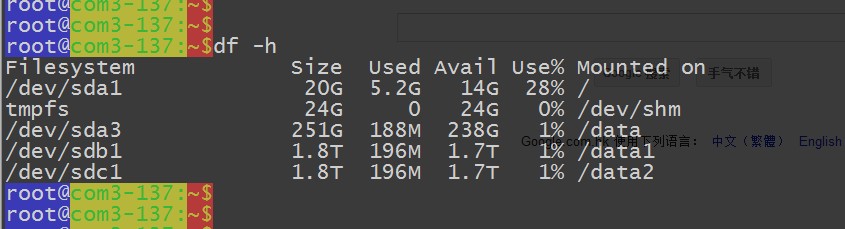
圖片 15.3 pic
既然說好了是在 python 下的應用測試,那就需要安裝 mongodb python 下的模塊!對了,不知道 mongodb-server 的安裝要不要說下?
cat /etc/yum.repos.d/10.repo[10gen]name=10gen Repositorybaseurl=http://downloads-distro.mongodb.org/repo/redhat/os/x86_64gpgcheck=0
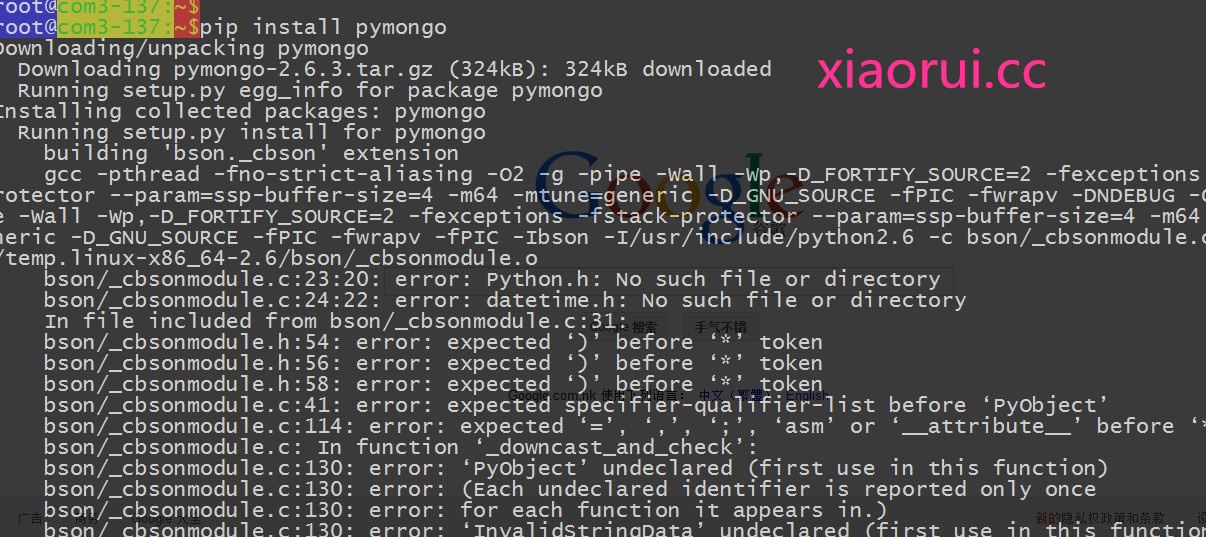
圖片 15.4 pic
Pymongo 的基本用法
from pymongo import * # 導包con = Connection(...) # 鏈接db = con.database # 鏈接數據庫db.authenticate(\'username\', \'password\') # 登錄db.drop_collection(\'users\') #刪除表db.logout # 退出db.collection_names # 查看所有表db.users.count # 查詢數量db.users.find_one({\'name\' : \'xiaoming\'}) # 單個對象db.users.find({\'age\' : 18}) # 所有對象db.users.find({\'id\':64}, {\'age\':1,\'_id\':0}) # 返回一些字段 默認_id總是返回的 0不返回 1返回db.users.find({}).sort({\'age\': 1}) # 排序db.users.find({}).skip(2).limit(5) # 切片 測試的代碼:
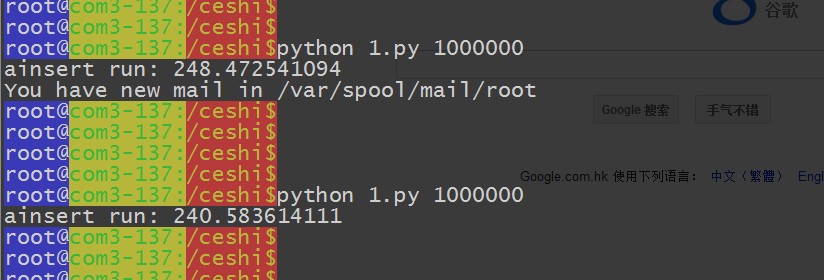
#!/usr/bin/env pythonfrom pymongo import Connectionimport time,datetimeimport os,sysconnection = Connection(\'127.0.0.1\', 27017)db = connection[\'xiaorui\']def func_time(func): def _wrapper(*args,**kwargs):start = time.timefunc(*args,**kwargs)print func.__name__,\'run:\',time.time-start return _wrapper@func_timedef ainsert(num): posts = db.userinfo for x in range(num):post = {"_id" : str(x),"author": str(x)+"Mike","text": "My first blog post!","tags": ["xiaorui", "xiaorui.cc", "rfyiamcool.51cto"],"date": datetime.datetime.utcnow}posts.insert(post)if __name__ == "__main__": num = sys.argv[1] ainsert(int(num)) 咱們就先來個百萬的數據做做測試~
綜合點的數據:
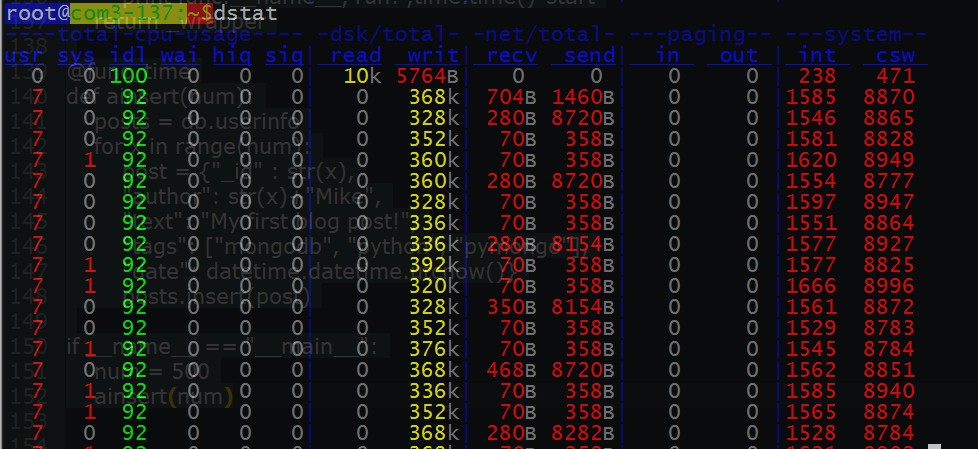
圖片 15.5 pic
在 top 下看到的程序佔用資源的情況 ~ 我們看到的是有兩個進程的很突出,對頭 ! 正是 mongodb 的服務和我們正在跑的 python 腳本!
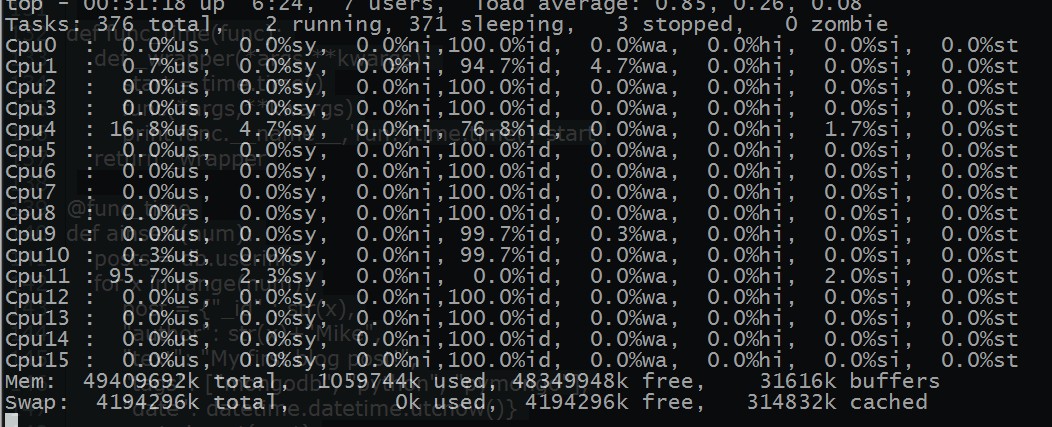
圖片 15.6 pic
看下服務的 io 的情況 ~
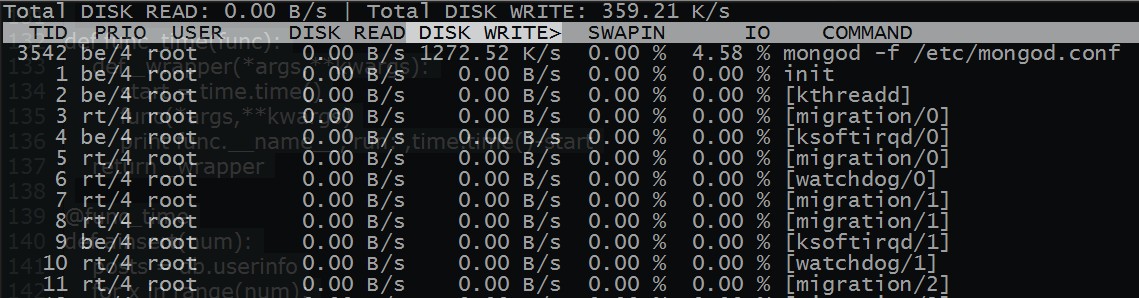
圖片 15.7 pic
腳本運行完畢,總結下運行的時間 ~

圖片 15.8 pic
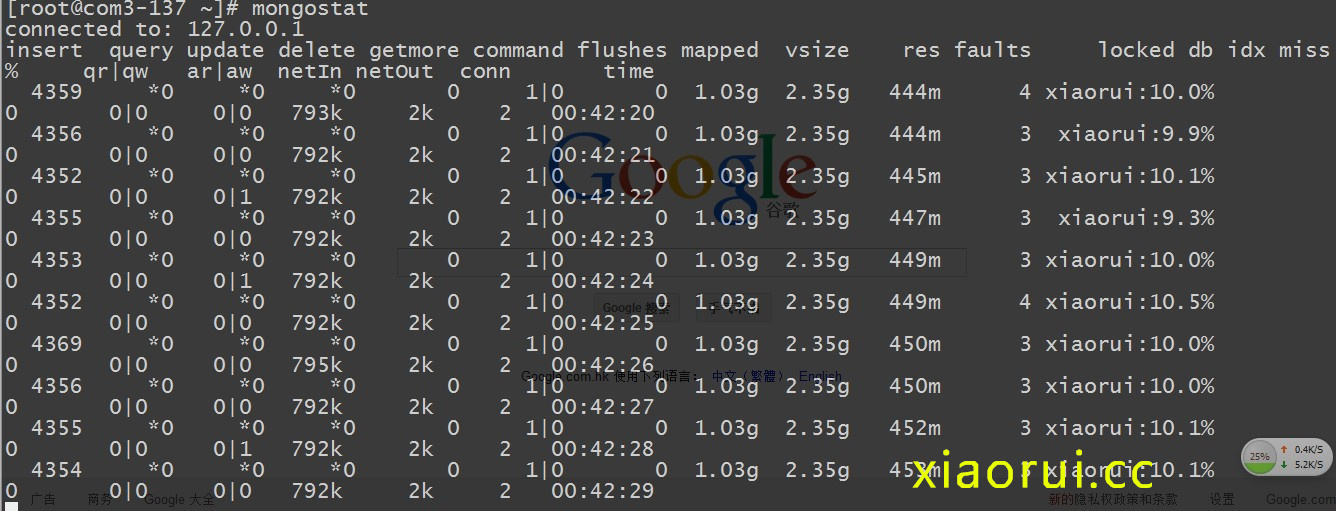
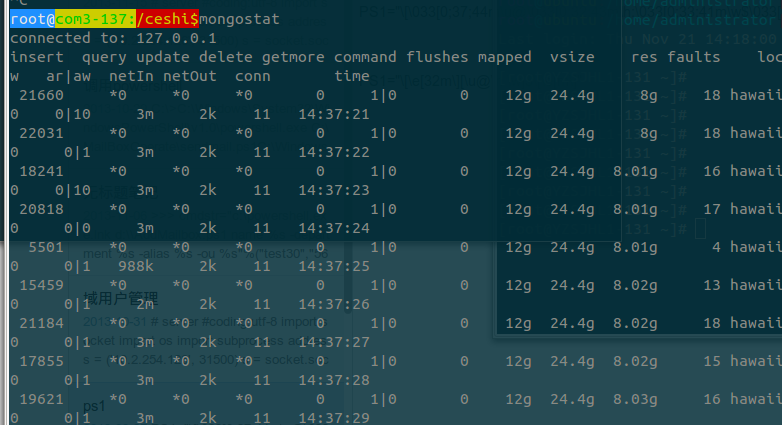
查看 mongodb 的狀態~
他的 insert 也不到 5k ~ 插入量也就 800k 左右 ~
它的輸出有以下幾列:
inserts/s 每秒插入次數
query/s 每秒查詢次數
update/s 每秒更新次數
delete/s 每秒刪除次數
getmore/s 每秒執行 getmore 次數
command/s 每秒的命令數,比以上插入、查找、更新、刪除的綜合還多,還統計了別的命令
flushs/s 每秒執行 fsync 將數據寫入硬盤的次數。
mapped/s 所有的被 mmap 的數據量,單位是 MB,
vsize 虛擬內存使用量,單位 MB
res 物理內存使用量,單位 MB
faults/s 每秒訪問失敗數(只有 Linux 有),數據被交換出物理內存,放到 swap。不要超過 100,否則就是機器內存太小,造成頻繁 swap 寫入。此時要升級內存或者擴展
locked % 被鎖的時間百分比,盡量控制在 50% 以下吧
idx miss % 索引不命中所佔百分比。如果太高的話就要考慮索引是不是少了
q t|r|w 當 Mongodb 接收到太多的命令而數據庫被鎖住無法執行完成,它會將命令加入隊列。這一欄顯示了總共、讀、寫 3 個隊列的長度,都為 0 的話表示 mongo 毫無壓力。高並發時,一般隊列值會升高。
conn 當前連接數
time 時間戳
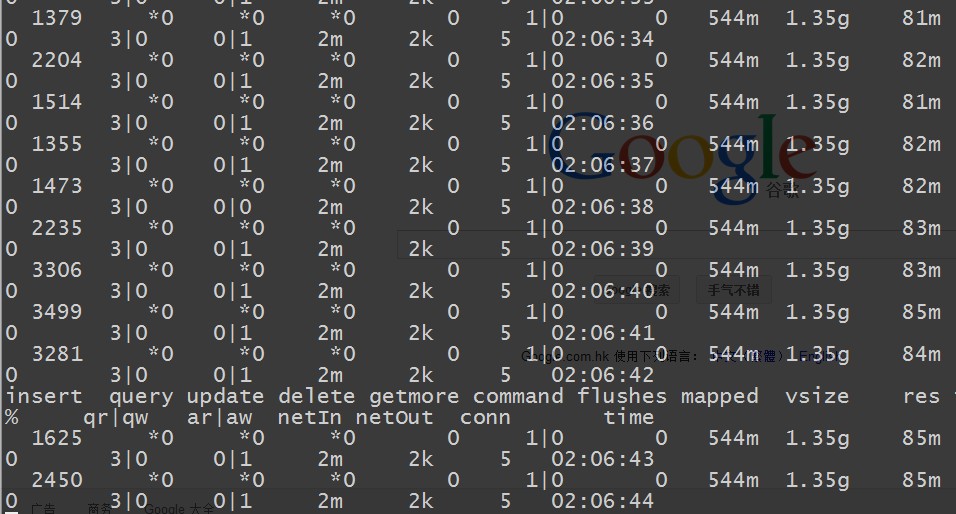
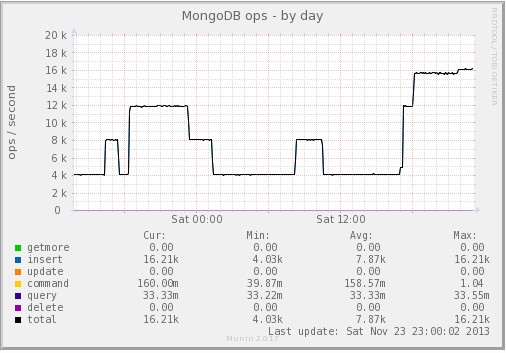
瞅下面的監控數據!
圖片 15.9 pic
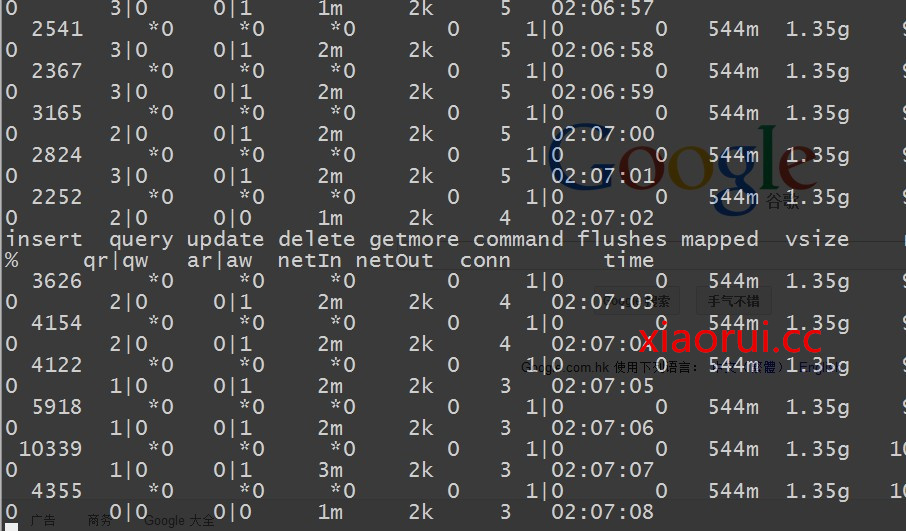
然後我們在測試下在一千萬的數據下的消耗時間情況 ~
共用了 2294 秒,每秒插入 4359 個數據 ~
圖片 15.10 pic
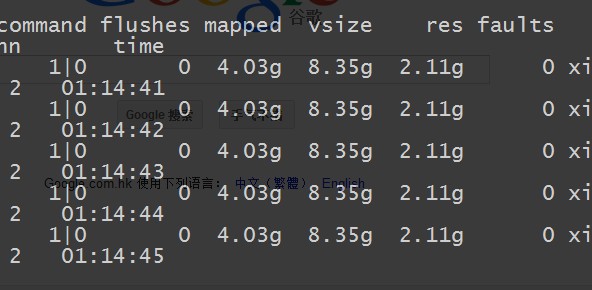
看看他的內存的使用情況:
虛擬內存在 8 gb 左右,真實內存在 2 gb 左右
圖片 15.11 pic
再換成多線程的模式跑跑 ~ 個人不太喜歡用多線程,這東西屬於管你忙不忙,老大說了要公平,我就算搶到了,但是沒事幹,我也不讓給你。。。屬於那種蠻幹的機制 ~
nima,要比單個跑的慢呀 ~ 線程這東西咋會這麼不靠譜呀 ~
應該是沒有做線程池 pool,拉取隊列。導致線程過多導致的。不然不可能比單進程都要慢~
還有就是像這些涉及到 IO 的東西,交給協程的事件框架更加合理點 !!!
def goodinsert(a): posts.insert(a)def ainsert(num): for x in range(num):post = {"_id" : str(x),"author": str(x)+"Mike","text": "My first blog post!","tags": ["mongodb", "python", "pymongo"],"date": datetime.datetime.utcnow} # goodinsert(post)a=threading.Thread(target=goodinsert,args=(post,))a.start 
圖片 15.12 pic
python 畢竟有 gil 的限制,雖然 multiprocess 號稱可以解決多進程的。但是用過的朋友知道,這個東西更不靠譜 ~ 屬於坑人的東西 ~
要是有朋友懷疑是 python 的單進程的性能問題,那咱們就用 supervisord 跑了幾個後台的 python 壓力腳本 ~ supervisord 的配置我就不說了,我以前的文章裡面有詳述的 ~
圖片 15.13 pic
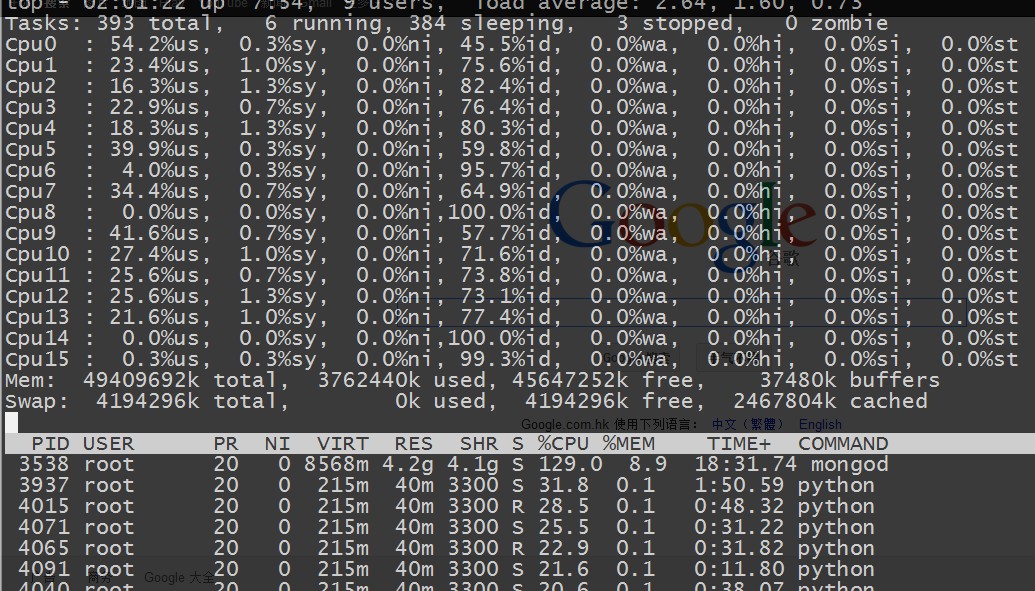
cpu 方面是跑的有點均勻了,但是 mongodb 那邊的壓力總是上不去
當加大到 16 個後台進程做壓力測試的時候 ~ 大家會發現 insert 很不穩定。 看來他的極限也就是 2 MB 左右的數據 ~
圖片 15.14 pic
當減少到 8 個壓力進程的時候 ~ 我們發現他的 insert 慢慢的提供到正常了,也就是說 他真的是 2 MB 的極限 ~
圖片 15.15 pic
腳本裡面是有做有序的 id 插入的,我們試試把 id 的插入給去掉,看看有沒有提升~
結果和不插入 id 差不多的結果 ~
圖片 15.16 pic
調優之後~ 再度測試
ulimit 的優化
cat /etc/security/limits.conf* soft nofile 102400* hard nofile 102400
內核的 tcp 優化
cat /etc/sysctl.confnet.ipv4.tcp_syncookies = 1net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_tw_recycle = 1net.ipv4.tcp_timestsmps = 0net.ipv4.tcp_synack_retries = 2net.ipv4.tcp_syn_retries = 2net.ipv4.tcp_wmem = 8192 436600 873200net.ipv4.tcp_rmem = 32768 436600 873200net.ipv4.tcp_mem = 94500000 91500000 92700000net.ipv4.tcp_max_orphans = 3276800net.ipv4.tcp_fin_timeout = 30 #直接生效/sbin/sysctl -p
啟動的時候,加上多核的優化參數
多核問題可以在啟動時加入啟動參數: numactl --interleave=all
insert 的頻率已經到了 2 w 左右 ~ 內存佔用了 8 G 左右 ~
圖片 15.17 pic
圖片 15.18 pic
我想到的一個方案:
當然不用非要 celery,就算咱們用 socket 寫分發,和 zeromq 的 pub sub 也可以實現這些的。這是 celery 的調度更加專業點。

圖片 15.19 pic
剛才我們測試的都是insert,現在我們再來測試下在千萬級別數據量下的查詢如何:
查詢正則的,以2開頭的字符
posts = db.userinfofor i in posts.find({"author":re.compile(\'^2.Mike\')}): print i 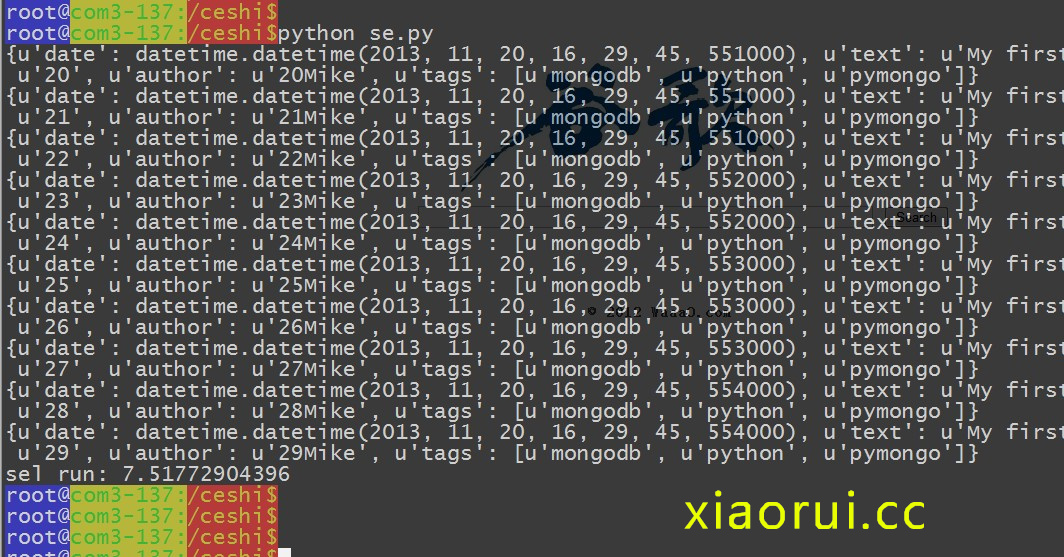
圖片 15.20 pic
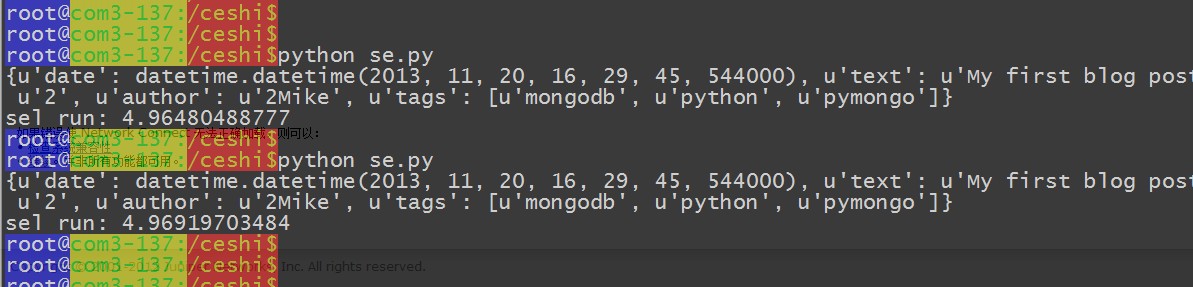
精確的查詢:
查詢在 5s 左右 ~
圖片 15.21 pic
圖片 15.22 pic
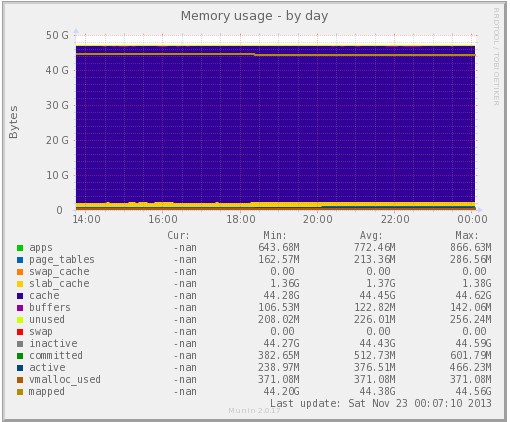
圖片 15.23 pic
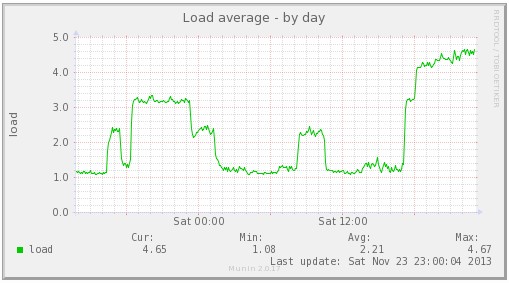
圖片 15.24 pic
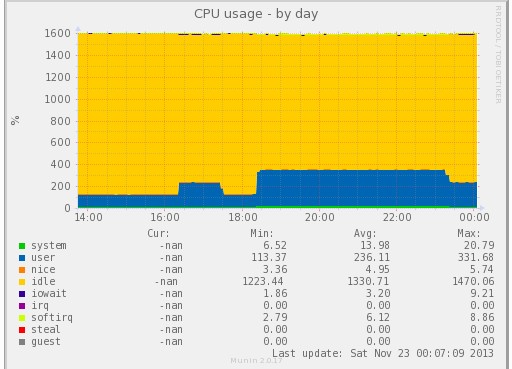
圖片 15.25 pic
總結:
典型的高讀低寫數據庫!
本文出自 「峰雲,就她了。」 博客,謝絕轉載!