「錯誤的旗桿」
如果是一些基礎性的因素,比如網點選址、產品線或者產品,不能夠與客戶需求相適應,那麼就算產品再智能、合作夥伴再優秀,也無濟於事。遺憾的是,我們總是會以南轅北轍的標準來衡量這些因素。
網點選址十分重要。在決策過程中,應該遵循一定的邏輯,並聽取多方意見,尤其是在貿易領域。然而在現實中,很多選址決策是基於決策者自身的主觀邏輯的,並不是基於客觀因素。我們也可以這樣說,在規劃和優化選址的決策過程中,實踐情況與邏輯理論偏離甚遠。
事實上,用於驗證選址是否合理的統計學方法早就存在,並且經過了實踐的檢驗。從本質上看,這種方法並不特別複雜,而且在過去的10年中沒有發生太多根本性變化。在做出選址決策前,一般來說,我們要分析購買潛力、核心目標客戶的行動路線以及步道的使用頻率等。這樣分析的結果往往是,我們會讓一個新規劃的建築市場直接毗鄰其區域內最強勁的競爭對手,比如選址在一個擁有相似產品線的傢俱市場的正對面,未來可能還會為這些同一競爭領域的商家配套加油站等設施。
針對區位選擇的聚類分析造成了德國批發零售行業扎堆的現象,具有直接競爭關係的企業挨得很近,並且貿易模式也很相似。一位選址戰略家認為,導致這種「扎堆」現象的原因是「旗桿效應」。有時候,樹立這根旗桿意義非凡,它可以是一種優越性的象徵。在貿易領域,我們提到「旗桿效應」時,往往會引發數據使用中的理解誤區。當一個看起來非常具有吸引力的選址進入我們的視野時,我們總是會產生一種念頭,我們一定要把新址定在這裡。這樣做是有原因的,因為這個地點享有很高的關注度,並且與其他地方互通方便,因此具有戰略性價值。這些選址之所以能夠獲得我們的關注,也常常是因為重要的競爭對手已經在此處建立了一個網點,且這個網點多年來經營得很成功。
但是,絕大部分批發企業在網點發展過程中並沒有孕育出一種戰略去指導不同地區、不同經營模式的網點,憑借它們的產品去匹配客戶多元化的需求。一般情況下,我們會嘗試去建立一個新網點,然後利用在其他地區業已成熟的經營模式,去滿足客戶既存的(有宏觀市場調研數據支撐的)需求。不同地點的網點間差異巨大,顯見的包括網點大小、場地結構以及產品線等因素,大部分並未被考慮在內。在本書的第二部分,在談到客戶旅程的時候,我們已經提及這一點了。網點負責人的任務就是,利用成功的經營模式,去滿足具有區域特色的客戶需求。但是令人著急的是,只有要在做出選址和經營模式選擇的決策時,企業才會想要去分析具有區域差別化的客戶需求對選址策略的影響。這絕對是一個決定性錯誤。大型的貿易連鎖企業必須馬上著手研究針對不同市場的經營策略。智能數據冠軍企業也應該從客戶角度出發,持續地考慮選址決策的問題。理想的情況應該是這樣的:
☆第一步:首先要瞭解市場,把客戶進行分類並排出優先級,然後針對不同類別的客戶提出差異化的經營策略。在此過程中,需要注意客戶旅程情況,並且明確定義出網點經營模式的角色作用。
☆第二步:確定我們在網點選址過程中需要怎樣權衡哪些標準。
☆第三步:開放性地研究客戶的購買潛力。借助於捷孚凱(GfK)和尼爾森市場研究公司數據庫中的郵政編碼信息來研究,會相對容易一些。
☆第四步:將差異化的客戶購買潛力情況與自身選址、最重要競爭者的選址情況進行比較,發現市場空白點。
☆第五步:系統化地評估潛力區域內的客戶需求,評估有市場研究數據支撐的網點,評估既存的、有相似客戶潛力的網點的交易數據。
☆第六步:到這步,我們才開始去尋找具體的選址。雖然存在例外情況,但在一般情況下,我們要避免與強勁競爭者挨得太近。如果物理距離太近,那麼就要經受考驗,與已經「樹起旗桿」的競爭者相比,我們是不是能夠以一種全新的貿易模式去更好地滿足客戶需求。
☆第七步:利用可掌握的全部數據源,詳細地分析網點的微觀環境,比如,利用谷歌地圖系統性地檢測購物高峰期的交通情況。基於證據的決策是主觀態度的前提。
☆第八步:參考差異化的選擇標準,確定正確的選址和經營模式。
如果此時有人覺得這樣做很乏味,寧願借助智能手機數據去做大數據客流研究,我們覺得這也是可以的,但前提是掌握了相應的技術手段。其他人最好還是優先考慮一下上述智能數據解決方案。
美國沃爾格林公司借助Excel實現選址優化
每一個網點都具有區域特性,尤其是藥品銷售網點。擁有近7000個銷售網點的美國藥品銷售連鎖企業沃爾格林公司,在多年前採用了一種獨特的方式,對客戶的購買數據與住址信息進行了比對研究。結果發現,最大購買距離是兩英里!住址距離一個網點超過兩英里的客戶就基本不會去這個網點買藥了。基於這種數據研究結果,沃爾格林公司的企業戰略人員可以發現前文提到過的網點發展過程中的市場空白點,也可以發現網點量供過於求的情況。另一方面,研究結論更容易轉化為實踐,即企業負責人可以更好地去優化在每個網點投入的廣告宣傳預算。
沃爾格林公司主要通過在報紙上安插宣傳折頁進行廣告宣傳,這些廣告折頁會隨報紙被分發到全國所有有郵政編碼覆蓋的區域。研究人員利用Excel匯總數據信息,識別出哪些郵政編碼覆蓋區域與最近的藥品銷售網點間的距離大於兩英里。隨後,這些區域的廣告宣傳預算將被取消。沃爾格林公司通過這種方法,累計節省了500萬美元的費用支出,但銷售額卻絲毫沒有受到影響。
在正確的地點採用正確的銷售模式
在下一章我們會看到,數據是如何使多渠道貿易成為可能並促進其發展的。在此處我們先重點強調,在不同的銷售模式下,在與客戶直接接觸的過程中滿足客戶需求的能力,是在大多數行業和商業領域建立多渠道戰略的前提。迄今為止,尤其是在貿易領域,這一點被強烈地忽視了,因此這反而為我們提供了機遇,使我們有可能在激烈的市場變革中佔據競爭優勢。在貿易領域,大型的連鎖企業可以通過上面八個步驟很清晰地識別出哪些選址對全產品線網點來說是合適的,哪些客戶需要購買受監管類藥物,哪些位置適合設立快閃店,以及哪些地區的居民喜歡在下班的路上順便開車去便利店買東西。獲得這些認知不僅僅對建立新網點有幫助,對優化現存網點網絡也有益處。
在不同的銷售模式下,在與客戶直接接觸的過程中滿足客戶需求的能力,是在大多數行業和商業領域建立多渠道戰略的前提。
當然,這也不僅僅適用於分銷貿易,對B2B貿易也起作用。在B2B領域,有時更容易發掘這些認知的應用潛力,就比如我們在前文提到的一個智能數據項目中,優化一個中型家裝服務供應商的外勤資源那個案例一樣。
「二戰」之後,在德國經濟奇跡那些年,德國企業經歷了持續性的高速增長,幾乎沒有經歷經濟蕭條的階段。在這期間,這些企業的分支機構網絡也得到了生機勃勃的發展,但那時的發展主要是憑「直覺」。
借助郵政編碼和交易數據信息,在分析客戶需求的時候考慮到區域差別化的因素,這種方式與之前的市場滲透截然不同。在一些地區,外勤人數過多,但產生的經濟效益少。而在另一些區域,外勤人數又與客戶需求潛力不符,不能滿足市場競爭的需要。在數據的支撐下分析外勤人員到客戶處去的實際路程時間,我們會發現,其實是外勤營銷區域的劃分有問題。在直線距離規劃和路程規劃的輔助下,我們可以優化外勤人員的路程選擇。通過重新劃分外勤營銷區域,外勤人員整體的工作飽和度在原基礎上可提高20%,人均工作飽和度範圍從之前的60%~120%調整為基本每個外勤人員都可達到95%。
如果我們把數據在圖表中進行可視化疊加,我們可以直觀地總結出很多有意義的功能整合措施。加上一點兒對路程數據的統計學分析,我們很快就可以得到新的區域劃分方案,並重新進行資源配置。不需要關閉任何一個網點,也不用裁減僱員。此外,這也是一個長期的轉型方案,企業可以在後續逐步實踐。
無論是設計建設新的網點,還是從根本上重新規劃既存網點,都是一項長期的工作,遠比在紙面上基於數據提出的優化方案要複雜。如果親身參與到這項工作中就會發現,在實施過程中存在很多的限制和困難,比如投資額巨大、可支配用地面積有限、審批障礙重重、施工制度限制、長期租賃合同事宜、勞務法律制度要求、不同網點間員工的抵制情緒等。數據只能夠輔助我們做出關於網點發展的正確決策,並協助我們通過實驗項目獲得關於網點具體設計應用於實踐的認知。在跨越實踐中的種種障礙上,數據能做的十分有限。但是,在優化產品線方面,數據能發揮的作用就很大了。在促進供求關係協調並符合區域性特徵方面,數據是必不可少的,在某些情況下,我們甚至需要實時數據來監控供求關係平衡問題。

實時優化產品線
當美國氣象台預測佛羅里達州將有颶風時,不僅僅是當地的救災組織做好了應急準備,當地的沃爾瑪超市也備足了食品,以應對客戶購買需求的變化。超市會立即向恐受災地區派出貨運卡車,這些卡車負責向災區輸送物資商品,如桶裝水、壓縮液化氣筒、煤油燈、保質期較長的牛奶製品、烤麵包乾等。還有一種家樂氏公司的名叫Poptarts的華夫餅,甜甜的,質地有些黏稠,很多在嬰兒潮年代出生的人小時候經常吃這種華夫餅,它會讓人回憶起兒時和諧安寧的生活,因此在面臨危險的環境下,人們似乎特別愛買這種華夫餅。
沃爾瑪在掌握貿易客戶數據信息方面幾乎可以與亞馬遜比肩,算是世界上數一數二的公司,同時,沃爾瑪也是世界上為數不多的真正實踐大數據應用的公司之一,在數據應用領域已經取得了極大的競爭優勢。一場颶風的來臨,只能算是持續優化產品線過程中的一個顯性極端事件。沃爾瑪公司能夠做到實時監測某一地區多變的天氣數據,並能夠將監測結果與產品銷售數據關聯分析,隨後會將分析結果應用於產品供應及定價決策中。憑借此種做法,一方面,沃爾瑪公司具備了極其靈活的物流配送能力,成為20年來最具市場分析能力的市場競爭者之一;另一方面,沃爾瑪公司的倉儲成本顯著降低。
現階段,幾乎在所有的大型歐洲貿易企業的貿易研究項目中,都能發現一個基本的訴求,那就是盡快掌握像美國貿易企業那樣的數字化競爭實力,並用盡可能短的時間,優化自身的產品線,以滿足變化了的市場需求。樹立這樣的項目目標是有原因的:
智能地優化產品線,能夠使我們在數據的輔助下,更好地對標客戶需求,提高客戶價值,與此同時,還可以優化庫存、降低成本、提高市場營銷有效性。
然而,一件事情的結果,往往不如人們預想的那麼好,在這件事情上也是這樣。如果我們想系統性地優化產品線,成功與否在很大程度上取決於銷售和市場研究數據。試點市場和實驗室數據顯示,由於市場競爭情況的不同,實際的優化結果差異較大。在產品線確實存在優化空間的前提下,地區性的結果差異往往跟市場或企業領導者的經驗和市場直覺有關。如果一家貿易企業能夠將沃爾瑪公司視為自身數字化競爭力的榜樣,那自然是好的。但不是每一家企業都能夠做到像沃爾瑪公司那樣,通過系統性地分析交易數據和市場潛力數據,及時(最少按周)調整區域產品種類,(最少每日)調整產品定價,使供求相匹配,同時還能夠重點關注某一產品門類的情況。
智能數據冠軍企業通過以下5個步驟,獲得優化產品線的能力:
1.系統性分析購物車信息;
2.獲得靈活調整產品供給和產品定價的能力,並且能夠衡量調整結果;
3.關聯產品門類數據,以便於進一步優化產品線;
4.縮短使產品供給與產品定價相互匹配的時間(從按周到逐日,再到實時調整);
5.基於上述4個步驟的經驗,構建一套基於數據的,對其他市場、工廠、企業等領域具有推廣性的優化流程。
如果連鎖商店能夠堅持品牌定位管理,那麼對商品門類和產品種類的細分將取得成效。
產品種類、產品定價細化的作用是有限的,這並不難理解。因此,尤其是連鎖商店,還應該關注網點品牌定位的問題。如果一家位於柏林或慕尼黑的網點,在箱包區出售日默瓦行李箱,但是哈根和吉森市內的網點,卻在售賣不知名品牌的行李箱,那麼對消費者而言,這家連鎖商店的品牌定位將日漸模糊。
採用不同的形式去強化產品細分,這對大多數貿易企業來說都有好處,我們在這一點上是有共識的。如果連鎖商店能夠堅持品牌定位管理,那麼對商品門類和產品種類的細分將取得成效。再以一家大型食品商店為例,這家商店對它的客戶群體以及客戶需求進行了持續性的細化分析,然後這家商店將可實現根據不同網點主要客戶群體類型,將每家分支網點進行功能定位,將網點分為日常網點、中等網點和高檔網點三類。然而,這只是第一步。
根據不同的行業,採取不同的細化形式,這是十分有必要的,因為不同行業的網點,其功能可能是截然不同的。銀行網點就是一個很好的例子,汽車行網點也是。以前,人們在買某一輛車之前,平均要去車行逛4次,而現在,車主基本上去一次車行,就能決定是否購買。通過產品配置軟件、網絡瀏覽和汽車行的官網查詢產品信息,這個過程在「客戶旅程」中占比越來越大。顯而易見,從客戶的角度出發,汽車行的功能定位發生了根本性變化。其實,早在一二十年前,汽車生產商就意識到了物理網點功能定位的問題。當時,幾乎所有的生產商都在考慮多銷售渠道戰略並賦予物理網點新的功能定位。但是當時,我們對「到底哪種物理網點定位才是符合未來發展趨勢」的認識還很少。從汽車生產商和銷售商的角度,謀求物理汽車行網點的替代性轉型,仍然需要嘗試和探索。
所有智能數據解決方案都需要遵循的一個根本原則是,要處理好投入與產出的關係,這也同樣適用於上文提到的方法和措施。在實際工作中,要想處理好投入與產出的關係,能夠衡量和量化產出是大前提。此時,基於數據的產品線優化就顯得十分必要了,因為只有基於產品優化細分,我們才能夠為解決方案的每個階段設計合適的對照組試驗,進而才能夠從根本上推動轉型。
DDI,這三個字母在全世界數字化復興時期獲得了廣泛關注。DDI是Data Driven Innovation的縮寫,即數據驅動創新。在理解或者介紹數據驅動創新這個概念時,人們往往會提到其帶來的破壞性影響。我們承認數據的破壞性影響力,並且在《我們的數據》一書中詳細描述了數字能夠產生破壞性影響力的原因。與此同時,我們也相信,改變人們對數據影響力的看法只是時間的問題,人們會意識到,在某些領域使用某些數據,將會給世界帶來改觀,將對企業及其市場、銷售部門產生積極影響。只是現在,人們還熱衷於關注數據驅動創新帶來的破壞性的威脅,而不是進步。
數據驅動創新可分為三個層面:
1.數字化技術創造全新的產品和服務;
2.在數據的支撐下,將會孕育出前所未有的商業模式;
3.在數據的輔助下,通過反覆的對照組試驗,逐步優化既存的產品、服務和流程。
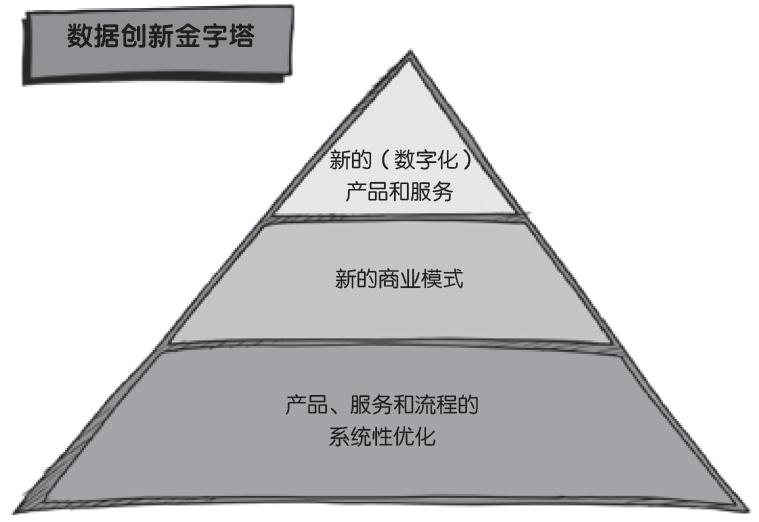
在與企業家交流的過程中我們發現,大多數企業決策者都對前兩個層面極其感興趣,而對第三個層面關注太少。一家德國汽車生產企業不斷地思考,如何能夠生產出無人駕駛汽車,這自然是有意義的。同樣,保險公司的產品研發部門去考慮,在汽車司機可以通過地理數據服務器將他們駕駛車輛的信息和行車信息實時地發送給保險公司的情況下(即使現在還做不到這樣),是否可以研發出一個新的個人保險險種,這也是有必要的。
然而,智能數據冠軍企業往往會從第三個層面著手,並且在流程長效優化方面傾注最多的資源。例如下列四項智能產品創新案例:
☆一家大型的運動鞋生產企業引導其客戶使用個人跑步App。通過研究App使用數據以及特定款式鞋類的銷售數據發現,購買某一款頂級跑鞋的消費者,在使用跑鞋方面存在極大差異。基於此種認識,這家企業改變了這款跑鞋的產品定位,將購買這款跑鞋定義為健康生活方式的象徵,並且針對特定的消費群體展開了相應的廣告宣傳。通過這種方式,這家企業促使特定消費群體的生活方式更加健康,另外,通過改變產品定位和市場宣傳這兩種手段,企業的營業額獲得了大幅提升。
☆有一家德國大型家用電器生產企業,對自身產品在東歐地區的銷售表現不滿意。於是,這家企業盡可能搜集了自己和競爭對手產品的市場、價格以及產品特徵等數據。這些數據一部分來自數據庫,另一部分由一家專業的產品標準管理組織提供。通過數據分析發現,在對產品購買決策影響較大的產品特徵方面,東歐和西歐地區是截然不同的,差異之大遠超這家德國生產商的想像。在認識和把握這種差異性方面,亞洲的競爭者似乎表現得更好,或是有更好的數據信息支撐。比如,一個藍色的、黃油塊兒大小的LED(發光二極管)燈泡,俄羅斯的消費者就會願意多付出50歐元去購買。一個小小的產品特徵改良,可能就足以提高產品在客戶心中的價值表現。
☆對一家電信供應商來說,消費者最關心的產品特徵就是,手機信號的接收質量是否良好。可惜的是,建造和運營通信網絡的成本,偏偏是這個行業最大的成本支出科目。一家阿拉伯地區的通信網絡供應商在早年便面臨市場挑戰,網絡傳輸能力的建設跟不上快速增長的市場需求。這個問題使這家通信網絡供應商面臨客戶因不滿意通信質量而加速流失的風險。因此當時,這家通信網絡供應商的決策層在建設和運營網絡方面追加了數十億美元的投資。如果這個案例發生在一個智能數據項目中,我們會建議這家企業的決策層首先去差別化地關注一下區域客戶潛力,然後參考每個通信基站覆蓋區域內的客戶價值貢獻,以及服務滿意度尚高的客戶群體的追加銷售潛力,再來規劃網絡擴建的進度。這樣做的話,只需要利用海杜普(Hadoop)軟件就可以提取分析交互數據,成本支出可能也就5位數。相比數十億美元的追加投資來說,豈止是合算可以形容的。
☆「Emmas Enkel」是小型便利店的迭代產物,即那種新式的、很小規模的、根植於當地消費需求的零售店舖。這些店舖要從8萬多件商品中挑選出幾千件適合於地區銷售的商品,僅依靠直覺恐怕是不行了。現在,它們持續性地關注並利用銷售數據,從而做到使所售商品與服務的小區域內不斷變化的市場需求相匹配。